

(香港综合讯)中国一家初创企业成功以较低成本开发出能比拟ChatGPT的大语言模型(LLM)。
总部位于杭州的DeepSeek星期四(12月26日)在微信公众号称,DeepSeek-V3在多项评测成绩中超越了meta开发的Llama-3.1,并在性能上与OpenAI开发的闭源模型GPT-4o不分伯仲。
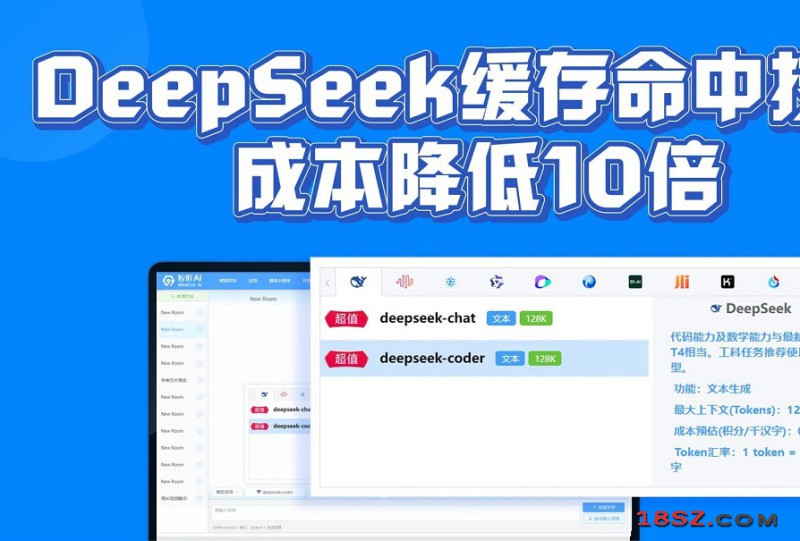
据《南华早报》报道,在较高性价比的新训练架构下,DeepSeek的训练成本仅558万美元,训练时长仅两个月,远低于GPT-4o逾1亿美元的成本及约三个月的训练时长。
DeepSeek在训练过程中仅使用2048个英伟达为中国市场定制的H800晶片,而据估算GPT-4o至少使用了上万个更先进的H100晶片来训练。美国禁止向中国出口H100晶片。
上海计划明年底建成世界级人工智能产业生态

中国上海市发布人工智能实施方案,计划到2025年底建成世界级人工智能产业生态。
上海市政府官网星期五(12月27日)发布《关于人工智能“模塑申城”的实施方案》。
根据方案,上海计划到2025年年底,建成世界级人工智能产业生态,力争全市智能算力规模突破100EFLOPS(EFLOPS是指每秒进行百亿亿次浮点运算),形成50个左右具有显著成效的行业开放语料库示范应用成果,建设三至五个大模型创新加速孵化器,建成一批上下游协同的赋能中心和垂直模型训练场。

方案共22条,其中对人工智能关键生产力工具的打造以及人工智能在重点垂直领域的应用有明确规划。
在“加快关键生产力工具打造”上,上海聚焦五项,即:智能终端、科学智能、在线新经济、自动驾驶和具身智能。

另一方面,上海计划推动重点垂直领域的应用。垂直领域的相关应用一直备受关注,此次方案明确了上海聚焦的六大领域,即:金融、制造、教育、医疗、文旅和城市治理。
上海也将从基础底座、应用生态等多方面着手,抢抓人工智能发展机遇。
 Iteca Exhibitions
Iteca Exhibitions 长城润滑油
长城润滑油 German Machine Tool Builders Association
German Machine Tool Builders Association 延长石油
延长石油 3M制造业
3M制造业 陕煤化工集团
陕煤化工集团 HUAWEI
HUAWEI Dahua Technology
Dahua Technology 中国石油
中国石油 Gemtique
Gemtique KUNVII
KUNVII PALEXPO
PALEXPO IAA Show
IAA Show LASTON
LASTON 中杭贸易
中杭贸易 Etek Europe
Etek Europe PV EXPO
PV EXPO QIIE青岛进博会
QIIE青岛进博会 陕西有色金属
陕西有色金属 维远光伏产业
维远光伏产业 Time Out Group
Time Out Group IFEMA
IFEMA 天元化工
天元化工 National Media
National Media 吉祥星科技
吉祥星科技 Dowpol Chemical
Dowpol Chemical 海康威视-HIK VISION
海康威视-HIK VISION Hannover Messe
Hannover Messe TOSHIBA
TOSHIBA Productronica
Productronica HealthCare
HealthCare 深圳会展中心
深圳会展中心 大唐旗舰店
大唐旗舰店 Soul Game
Soul Game 神木职教中心
神木职教中心 Sinopec
Sinopec 中国有扇越开越大的门
中国有扇越开越大的门 四川隆昌传承千年土陶艺
四川隆昌传承千年土陶艺 崔培鲁《艺术传承书画同源》画展采访
崔培鲁《艺术传承书画同源》画展采访 ILA Berlin 2020 - 柏林国际航空航天博览会
ILA Berlin 2020 - 柏林国际航空航天博览会 第二届进博会将至 航拍璀璨夜上海
第二届进博会将至 航拍璀璨夜上海 2021年秋季艺术品拍卖会水墨葡萄90万成交
2021年秋季艺术品拍卖会水墨葡萄90万成交 鸿华物流运输车
鸿华物流运输车 一首歌一座城·江苏无锡《太湖美》
一首歌一座城·江苏无锡《太湖美》 新冠病毒灭活疫苗获批进入临床试验
新冠病毒灭活疫苗获批进入临床试验 中老铁路开通运营【图集】
中老铁路开通运营【图集】 2019年埃森国际野外旅游展览会
2019年埃森国际野外旅游展览会 拜登与贺锦丽就任美国第46任总统与副总统
拜登与贺锦丽就任美国第46任总统与副总统 DowSyn 改进剂
DowSyn 改进剂 侨城坊现今艺术展厅之日本画家冈本作品展参观图集
侨城坊现今艺术展厅之日本画家冈本作品展参观图集 陕北特产五谷杂粮
陕北特产五谷杂粮 北京论坛(2019)在京开幕
北京论坛(2019)在京开幕 2022年秋季广州美博会-2022年9月份广州美博会
2022年秋季广州美博会-2022年9月份广州美博会 长征者-开国少将廖鼎琳油画
长征者-开国少将廖鼎琳油画 海口港进口报关公司|三亚进口报关公司
海口港进口报关公司|三亚进口报关公司 家庭医疗健康及康复医疗展-2024深圳国际医疗器械展览会
家庭医疗健康及康复医疗展-2024深圳国际医疗器械展览会 山东济南医疗用品展|2025第53届中国国际医疗器械博览会
山东济南医疗用品展|2025第53届中国国际医疗器械博览会 洛阳瑞克再售YA3080振动筛设备
洛阳瑞克再售YA3080振动筛设备 2025北京国际自动驾驶技术展览会
2025北京国际自动驾驶技术展览会 SM商用显示器
SM商用显示器 意大利里米尼城市介绍
意大利里米尼城市介绍 纽伦堡 - 玩具都城
纽伦堡 - 玩具都城 慕尼黑 - 伊萨尔河畔的酒都
慕尼黑 - 伊萨尔河畔的酒都 法兰克福 - 欧洲金融中心
法兰克福 - 欧洲金融中心 迪拜 - Dubal
迪拜 - Dubal 俄罗斯 - 战斗民族和套娃的国家
俄罗斯 - 战斗民族和套娃的国家 葡萄牙 - 软木塞之乡
葡萄牙 - 软木塞之乡 西班牙 - 斗牛士的故乡
西班牙 - 斗牛士的故乡





